

Learn how and why independent publishers should block thieving bots via Robots.txt, while allowing regular search engines through.
As a writer and independent creator, I’ve poured countless hours, months, weeks, years, decades into research, reading and firsthand experiences to craft articles for newspapers, wires, magazines and finally websites.
The beauty of the free, open web was that anyone, almost anywhere could create a website and maybe a living.
That was the magic. A domain, a spark, and sweat equity could give you a shot.
In my long journey as a web publishers, I’ve loved seeing and meeting whiz kids from developing countries who had set themselves up with a sustainable online business through pure sweat equity and against all odds (like unreliable internet and old equipment, hello! ).
Then the tech colonization of the open web and the roll out of AI in the last through years smothered one of the rare no capital investment required, merit-based professions of the early millennium.
You can still spin up a site for free — even GitHub hands out hosting — and of course the old blogging platforms never left.
The tools are cheap.
What costs now is visibility.
The Web Was Built for Humans. Then Came the Hungry, Hungry Corporate Hippos
The moment AI systems began ‘aggregating’ our work and Google narrowed its search gaze to ‘buyer intent,’ the web stopped being a place made for humans.
Now it’s an increasingly gated ecosystem patrolled by corporations and bureaucracies, where independent voices get drowned unless they’re feeding a corporate algorithm.
The irony is that almost everyone online is affected — even people whose income doesn’t depend on publishing.
Anything you post anywhere — a review on social media, an opinion, a joke — it all ends up shoveled into training data.
Social media used to hand our details to advertisers and the usual institutional voyeurs; now it feeds them straight into a plagiarism mill.
This nonconsensual harvesting of insight and labor isn’t just annoying — it undermines the basic autonomy of ‘thinking in public.’
Machines trawl our work constantly, prodding and absorbing like Pac-Man on power pellets.
You put in the research, the interviews, the fact-checking, the years of experience and some opaque system chews it up and sells the predictive spit-out.
So the question becomes: if they’re going to steal our work and labor incentives, how do we make it harder?
The Rise of Uncredited AI Consumption
AI boosters love to frame this era as a grand step forward for humanity.
Maybe it could be — if the whole system weren’t powered by a commercial engine that treats other people’s work as an all-you-can-eat free buffet.
As with every ‘privacy setting’ we’ve ever been handed, it’s built on an opt-out model.
We put our work online for actual readers, but anyone running a website knows that most of the so-called ‘traffic’ is really a swarm of bots and scrapers vacuuming up material for training sets.
The data already absorbed into those models is gone; there’s no rewind button.
What we can do is decide who gets to keep scraping us going forward.
When I first blocked every bot I could identify — including the ones that weren’t exactly forthcoming about their user agents (Meta’s training crawler hides behind the extra greedy meta-externalagent, if you’re curious) — I still saw my work appear on certain AI platforms. That pushed me to rethink the approach.
The reality is that some AI systems still send readers back through actual citations, the way Google once did before its own makeover made organic traffic evaporate.
Others just strip the content, keep the value for themselves, and leave you with nothing.
And that’s where my stance has landed: independent publishers should shut the door on models that quietly mine without giving anything back, and leave it open for the ones that at least return the favor with attribution and real reader traffic.
Since I wrote this I have come across more comprehensive instructions, such as these.
What follows is just my approach.
Protect Your Work: Become a 404 Sensei
According to tests done by the team at Ahrefs blog, when people inquired about specific brand names, the LLMs were stingy providing links that would take people off their site.
As you can see from the list below according to their tests, Perplexity was the most generous, providing a link slightly more than 50 percent of the time while Google’s AI Overviews was the most stingy model tested (shocking, I know).
Percentage of Times Language Learning Models Provided a Citation:
51.6% on Perplexity
36.8% on AI Mode
26.9% on ChatGPT
26.1% on Copilot
16.8% on Gemini
10.7% of the time on AI Overviews
VIA Robots.Txt
To safeguard my content, I initially implemented measures to block specific AI crawlers via Robots.txt:
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: meta-externalagent
Disallow: /
User-agent: FacebookBot
Disallow: /
User-agent: facebookexternalhit
Disallow:
These directives will instruct compliant bots not to access your site.
I allow facebookexternalhit because this is the bot responsible for previews when people share your content on Facebook, not that they give free eyeballs anymore though.
While not foolproof — since some bots may ignore these instructions — it’s a step toward asserting control over your own work and does work with more respectable scrapers, if there is such a thing.
I decided to only block bots that don’t provide citations.
Those that do will get you a click once in a while.
I found this wasn’t enough though, because robots.txt works on the honor system.
Robots.txt is basically a polite sign at the edge of your property that says: Private — Do Not Trespass
Well-mannered visitors read it, tip their ha t, and stay on the sidewalk.
It’s important to note that Robots.txt is no longer ‘set it and forget it’ and be aware of the deluge of new scrapers appearing daily, and update your Robots.txt as necessary.
Because the AI scrapers won’t necessarily follow directives, and behave more like house raiders.
They see the ‘no trespassing’ sign and stroll right past it.
Some hide their identity, some pretend to be something else, and some slip in through side doors by mimicking ordinary browser traffic.
They don’t care about your ‘Keep Out’ sign on the fence because nothing is actually stopping them at the boundary.
To keep them out, you need locks and a growling dog, not lawn signs — which is why server-level blocking (Cloudflare rules, firewalls, IP filtering) succeeds where robots.txt alone doesn’t.
Using Cloud Services:
Cloud services sometimes have their own automated bad bot blockers.
I use Cloudflare and tried it out, but I found that it would often require a bot verification page before getting to the site, so I turned it off. And then my site got hacked and I turned it back on again.
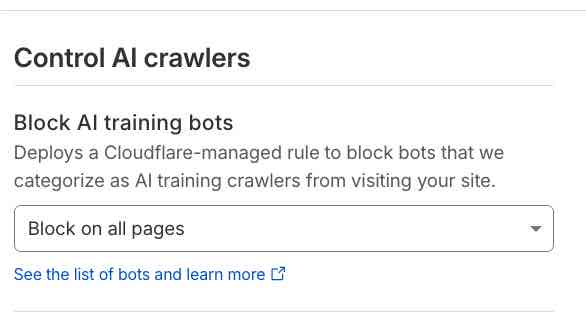
If that doesn’t bug you, it is a straight forward way to go.
Otherwise the placement depends entirely on the stack you’re running.
Here are the practical spots where that snippet (or a version of it) actually belongs:
1. Cloudflare Firewall Rules (most common)
If the site is behind Cloudflare, this expression is how its blocked via their Firewall Rule syntax.
Where to put it:
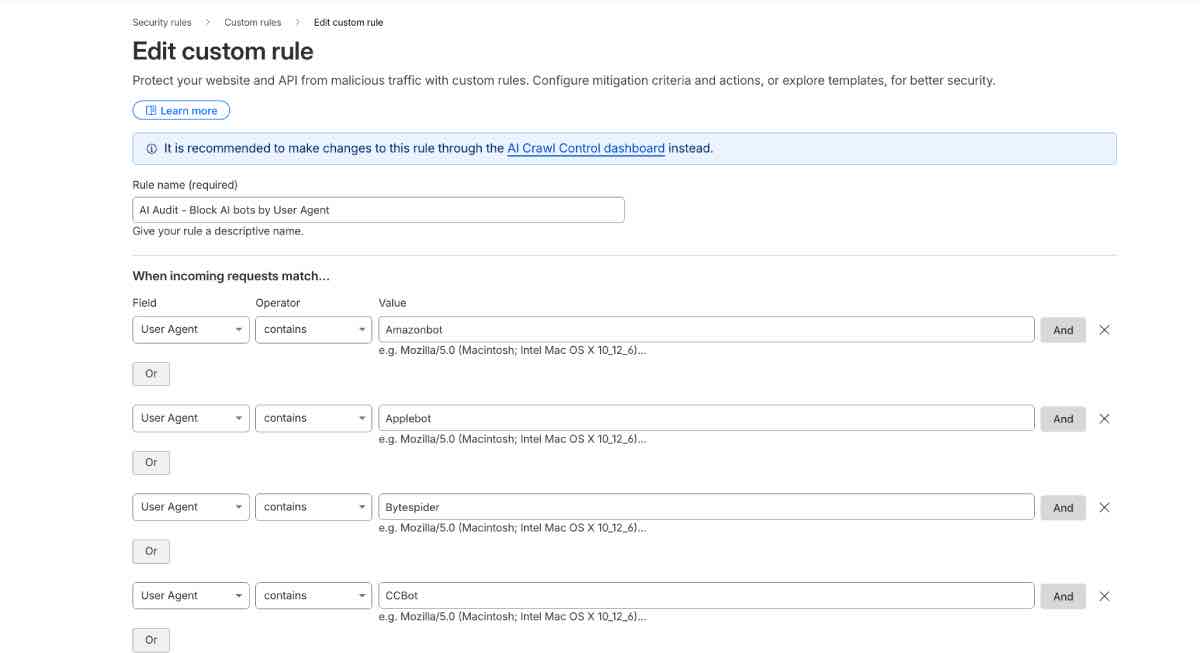
Dashboard → Security → WAF → Firewall Rules → Create a new rule →
Either do it manually putting ‘user agent’ in the field, ‘contains’ in the Operator and the bot you want to block in the Value area.
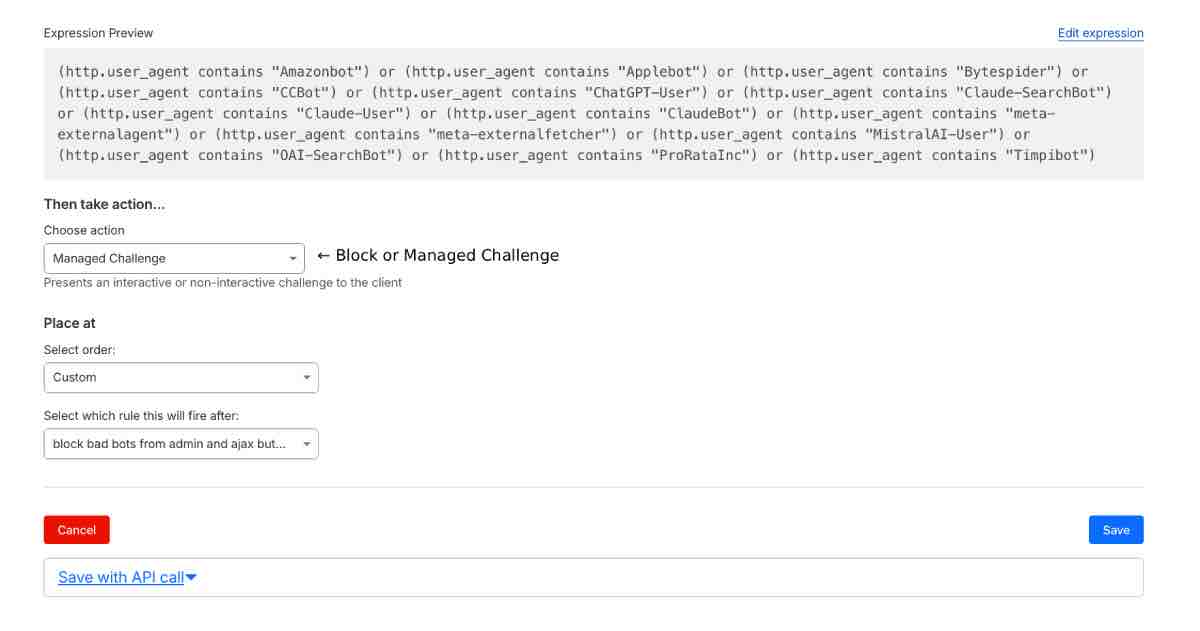
Or just paste the expression into the Expression Editor:
(http.user_agent contains “Amazonbot”) or (http.user_agent contains “Applebot”) or (http.user_agent contains “Bytespider”) or (http.user_agent contains “CCBot”) or (http.user_agent contains “ChatGPT-User”) or (http.user_agent contains “Claude-SearchBot”) or (http.user_agent contains “Claude-User”) or (http.user_agent contains “ClaudeBot”) or (http.user_agent contains “meta-externalagent”) or (http.user_agent contains “meta-externalfetcher”) or (http.user_agent contains “MistralAI-User”) or (http.user_agent contains “OAI-SearchBot”) or (http.user_agent contains “ProRataInc”) or (http.user_agent contains “Timpibot”)
This is the cleanest option; no server config edits, and it updates instantly.
Should You Block Bad AI Bots with Managed Challenge or Straight Block?
A JS challenge gives you a layer of hesitation rather than a slammed door.
It lets real browsers through automatically while most automated crawlers fail the test, which is useful if you’re not entirely sure a user-agent is hostile or if you want to watch its behavior before cutting it off.
It also tends to create less chaotic traffic because some bots respond to a hard block by retrying in bursts (which you can surely observe yourself by looking at logs).
A straight block is cleaner and more decisive.
If you already know the traffic is worthless or parasitic, this is the simplest way to stop it cold.
The downside is that if you misidentify something—say a social media preview-fetcher or a service your site quietly depends on, there’s no graceful fallback — you just break the connection.
→ I initially set action to Block but discovered this caused some bots like the aholes at META to hammer the site relentlessly, so I changed it to managed challenged.
2. Nginx
I don’t use Nginx but you’d block these inside the server block. You’d rewrite it like:
if ($http_user_agent ~* "(Amazonbot|Applebot|Bytespider|CCBot|ChatGPT-User|Claude-SearchBot|Claude-User|ClaudeBot|meta-externalagent|meta-externalfetcher|MistralAI-User|OAI-SearchBot|ProRataInc|Timpibot)") {
return 403;
}
Where:/etc/nginx/sites-available/yourdomain (inside the appropriate server block).
Reload with nginx -s reload.
3. Apache
I’m on Apache but using Apache’s .htaccess rules feels almost old-school wizardry: you’re telling the server itself to slam the door on those bots before they even breathe on your site.
It’s fast, decisive, and works even if some bots ignore robots.txt.
The catch is that .htaccess rules get read on every request, which means they’re not the most efficient thing in the world if you pile on too many.
And if you misplace a quote or break the syntax, you don’t just block bots — you can faceplant your whole site until you fix it.
Cloudflare’s approach feels cleaner because the filtering happens upstream, before traffic ever touches your server.
That saves server resources, keeps your logs tidy, and makes experimentation safer.
The downside is you’re tied to what Cloudflare exposes in its interface, and if a bot spoofs its user agent cleverly, you’re depending on Cloudflare’s detection or your own expressions, which sometimes lag behind reality.
So Apache gives you direct control — raw and close to the metal — while Cloudflare is the bouncer at the door.
Both work. I chose the one that broke fewer things while building a newer version of a site.
For sites using Apache, this goes either in .htaccess or in the main <VirtualHost> block, but the syntax changes:
BrowserMatchNoCase "(Amazonbot|Applebot|Bytespider|CCBot|ChatGPT-User|Claude-SearchBot|Claude-User|ClaudeBot|meta-externalagent|meta-externalfetcher|MistralAI-User|OAI-SearchBot|ProRataInc|Timpibot)" badbot
Order Allow,Deny
Allow from all
Deny from env=badbot
Where:public_html/.htaccess — quickest place.
4. Cloud hosting load balancers / edge rules
Those working in a newsroom with platforms like Akamai or Fastly have rule engines where you paste expressions similar to Cloudflare’s.
Usually under “Access Control,” “Request Rules,” or “VCL Snippets” (for Fastly).
5. WordPress security plugins
As a last resort, if the other options aren’t available or too complicated, you can use a WordPress plugin and avoid server-level edits.
Plugins like All in One WP Security allow user-agent blocking lists directly in the UI. Performance is worse than server-level blocking, but it works in a pinch.
The Demand for Digital Decency
We shouldn’t even have to burn hours swatting away greedy scrapers instead of doing what we’re actually here for — making things worth reading.
I make it clear on my Terms of Service that I am not willingly making my work available to scrapers.
I’ve even created a custom clipboard injection to site the website source.
Tech keeps racing ahead like a toddler with scissors, and creators have to pick up the pieces (and probably get a second job).
If the people building these systems won’t police themselves, the least we can do is stop handing them our work gift-wrapped.
Because without real humans writing, reporting, thinking and bantering freely, what exactly do these models plan to feed on — ¿each other?
Blocking crawlers that don’t send a single reader your way isn’t a grand stand.
It’s just basic drawing of digital boundaries.
I hope putting a polite little fence around your online ‘yard’ will help keep the uninvited out while you get back to the real work instead of worrying that all you’re doing is helping corporation’s bountiful harvest.